Scripting Data Source
The Script data source allows you to use scripting to add data into a report, or modify existing data. With this data source, you can pull in data from the database and then modify it using a script before pushing it out as a data key for use in the report.
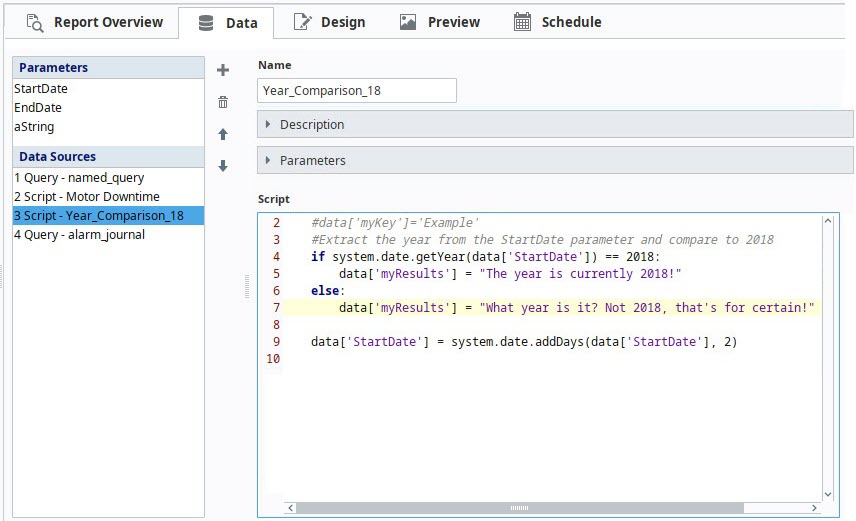
Accessing Parameters and Data Sources
One of the main uses of the Script data source is data access and manipulation as the report is being generated, allowing you to replace the original results, or add new additional content.
Simple data types, like strings and integers, are listed as Parameters. Datasets are listed as Data Sources. Script data sources can be given a name using the Name field.
As mentioned on the Report Data page, the order of data sources determines which parameters and data sources they may reference. Because of this, it is highly recommended that Script data sources are placed at the bottom of the Data Sources list.
Manipulating Parameters
Incorporate parameters in your scripting by using the 'keyName' as the name of your data key. This allows reading and manipulation of these values to use in your data.
For example, the initial StartDate parameter value can be accessed using system.date.getYear() and an if-statement.
# Extract the year from the StartDate parameter and compare to 2017.
if system.date.getYear(data['StartDate']) == 2017:
# Do work here if the year lines up.
We can also write back to the key and override its value:
# This line would override the default StartDate parameter by add adding a day.
data['StartDate'] = system.date.addDays(data['StartDate'], 1)
Additionally, this allows you to expand the Accessing a Parameter's Value example above by creating a new key, using the syntax shown below for creating or referencing a data key in the Script datasource:
data['newKey'] = "This key was generated on the fly!"
# Extract the year from the StartDate parameter and compare to 2017.
if system.date.getYear(data['StartDate']) == 2017:
# Create a new key and assign it one value if our condition is true...
data['myResults'] = "The year is currently 2017!"
else:
# Or assign a different value if the condition is false.
# This way we can always assume the key 'myResults' exists.
data['myResults'] = "What year is it? Not 2017, that's for certain!"
Data Sources
Static CSVs
Static CSVs may be accessed in a Script data source. The syntax is similar to working with parameters.
# Take a Static CSV data source, and replicate its contents in a new key.
data['static_data'] = data['Area Data']
Query-Based Data Sources
Reading the contents of a query-based data source, such as a SQL Query or Tag Historian Query, requires the getCoreResults() function, which returns the results in a standard dataset. The getCoreResults() function does not include nested queries in results, but you can refer to the Nested Queries section below for an example using getNestedQueryResults().
# Query-based data sources are slightly different than parameters,
# so we must use getCoreResults() to extract the data.
rawResults = data['keyName'].getCoreResults()
# getCoreResults() returns a dataset, so we can utilize getValueAt() and rowCount within our scripts.
resultsCount = data['keyName'].getCoreResults().rowCount
Once you have returned results for your dataset, you can apply extra filtering to write back. However, another approach is to create a new key with the modified results instead.
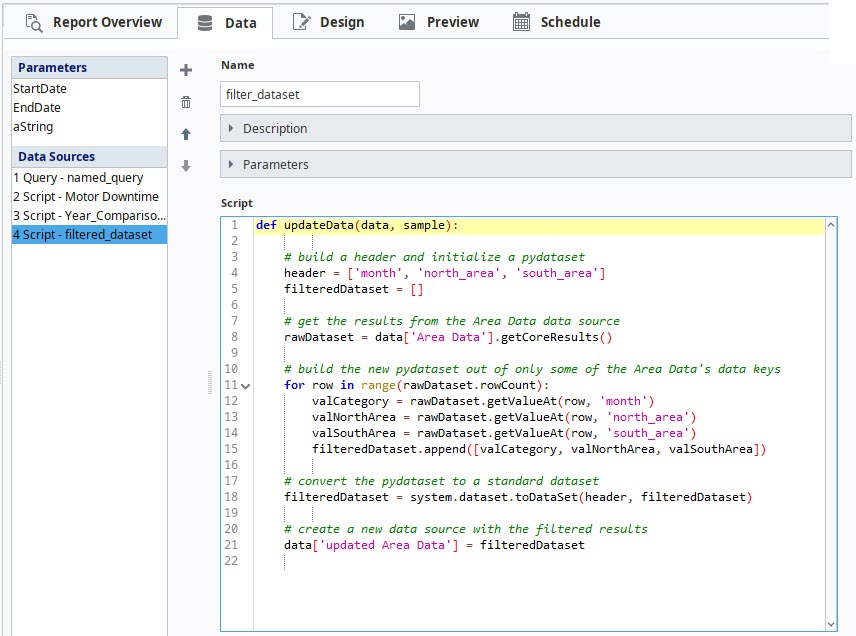
Say we have a query data source named "Area Data" which contains four columns: month, north_area, south_area, and t_stamp. If we need to build a new data source without the t_stamp column, we can use the following code:
# build a header and initialize a pydataset
header = ['month', 'north_area', 'south_area']
filteredDataset = []
# get the results from the Area Data data source
rawDataset = data['Area Data'].getCoreResults()
# build the new pydataset out of only some of the Area Data's data keys
for row in range(rawDataset.rowCount):
valCategory = rawDataset.getValueAt(row,'month')
valNorthArea = rawDataset.getValueAt(row,'north_area')
valSouthArea = rawDataset.getValueAt(row,'south_area')
filteredDataset.append([valCategory,valNorthArea,valSouthArea])
# convert the pydataset to a standard dataset
filteredDataset = system.dataset.toDataSet(header, filteredDataset)
# create a new data source with the filtered results
data['updated Area Data'] = filteredDataset
Nested Queries
It might be helpful when using Table Groups to have a nested query that can be manipulated in a script. The example below demonstrates this with our Area Data query and a nested query called Area Details using the getNestedQueryResults() function.
nested = data['Area Data'].getNestedQueryResults() # Gets results from our parent query
subQuery = nested['Area Details'] # Gets the subquery we want -- there can be more than one
header = ['productName', 'cost', 'triple']
alteredDataset = []
for child in subQuery:
children = child.getCoreResults() # children is a dataset
for row in range(children.rowCount):
valProductName = children.getValueAt(row,'productName')
valCost = children.getValueAt(row,'cost')
valTimesThree = None
if valCost != None:
valTimesThree = 3 * valCost
alteredDataset.append([valProductName,valCost,valTimesThree])
# convert the pydataset to a standard dataset
alteredDataset = system.dataset.toDataSet(header, alteredDataset)
# create a new data source with the altered results
data['Updated Area Details'] = alteredDataset