SQL Query Volume Optimization
Overview
Leveraging a SQL Database can drastically improve the quality of a project, but improper database consideration while designing can lead to poor performance later on. This page contains some best practices and considerations when incorporating SQL queries.
Optimizing Individual Queries
Optimizing individual queries to run faster and be more efficient is very difficult to do properly and can vary widely depending on a number of factors such as the way the tables are setup in the database and what data is being pulled out. Because each database can vary widely from another, there isn't any general way of improving the efficiency of your queries. Instead we recommend becoming more familiar with the SQL language as well as how the data is setup in your system and exactly what data you want to retrieve. This knowledge can help you build better queries.
Your company may also have a database administrator who would manage the database system for your company and would be familiar with figuring out the best way of retrieving data. They may be able to help you retrieve the data that you need.
Always Think Large
Consider how many instances of a query may be running at any given point in time. A single SQL Query Binding will be called for each instance of the window that is open, so if 50 clients are all looking at the same window, 50 separate queries will be called. If the binding is configured to poll, then 50 queries will poll at the rate specified for this single binding. This is already a fair amount of work without factoring in other systems, such as Tag Historian.
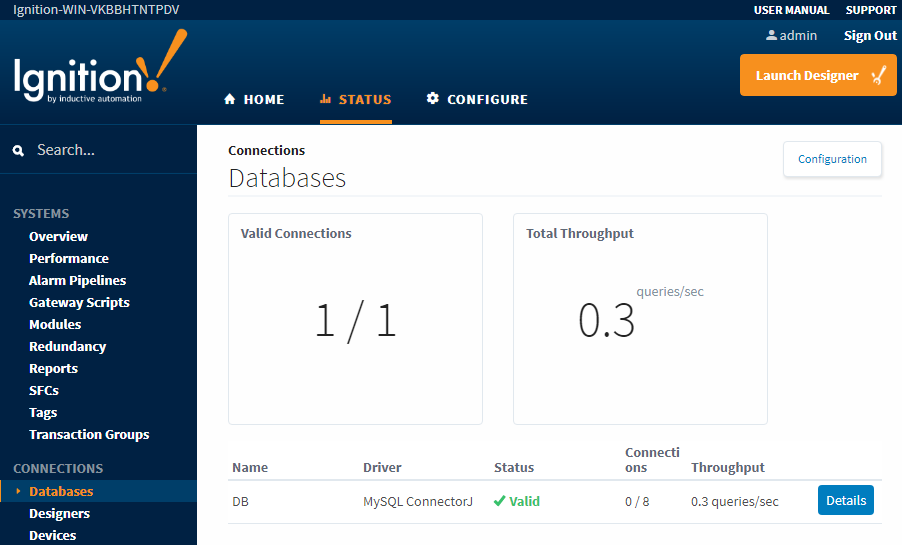
To provide context, you can always check the Status Section of the Gateway Webpage to check current throughput of each database connection.
Use Cached Named Queries When Possible
Most resources in Ignition that can request a query will not cache the results for use by other resources: a SQL Query Binding that returns a result set will only do so for the one component, and can't be utilized by other resources in the same project. Thus, if two clients have the same window, the same query must be fired twice for both bindings to receive information from the database which is wasteful.
Named Queries are the exception. They can cache the resulting dataset for use by other resources in the project, as well as other instances of the same project. In the previously mentioned scenario, one client would trigger the Named Query to execute, and the other client would simply utilize the cached result set, reducing the number of queries running against the database.
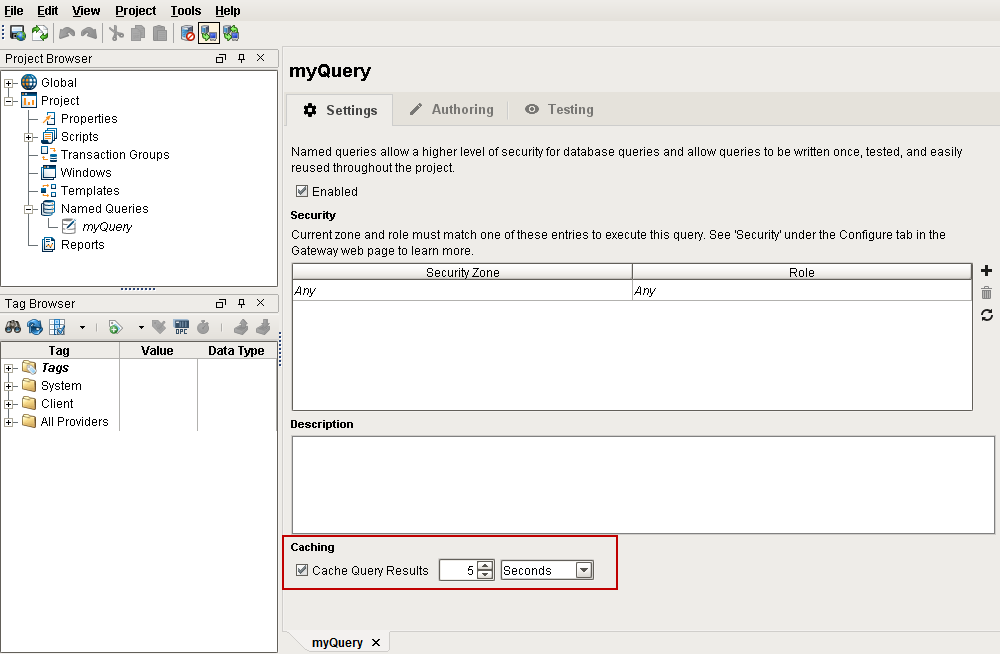
If your project contains queries that poll slowly, or results sets that aren't frequently modified, then a Named Query with caching enabled is an efficient alternative to a SQL Query or DB Browse binding.
Use the Expression Language to Consolidate Multiple Queries
If multiple resources (such as multiple Tags, or multiple components) need separate values from the same database table, or a window contains multiple components that are all querying data from the same table, such as multiple Numeric Labels, it may be more efficient to have a single query run and fetch the large portions of the table, and then distribute the individual values to each component. This typically involves having some property or Tag query for several rows of data from a database table, and then using expression bindings or Expression Tags to retrieve individual values from the query.
Individual values may be retrieved from a dataset via the Expression Language: either an Expression binding on a property, or an Expression Tag. Here are two commonly used approaches to extracting a single value from a dataset in the Expression Language:
- The Expression Language's Dataset Access syntax. You may want to use the try() function in case the dataset is empty:
Pseudocode - Expression Language Dataset Access Syntax
{dataset}[rowIndex,columnIndex] - The lookup function:
Pseudocode - Expression Language Lookup Function
lookup({dataset}, lookupValue, noMatchValue)
Restrict the Number of Query Tags in a UDT
Each Query Tag in a UDT will run a separate query per instance of the UDT. Assuming a scan class of one second, if a UDT definition contains 5 Query Tags, and there are 5 instances of that UDT, then there will be 25 queries executing every second.
As mentioned on this page, the Expression Language can be used to reduce load on the database if multiple Query Tags are retrieving data from the same database table. Furthermore, UDT parameters can be utilized in the Expression Tags, so new UDT Instances can easily be configured to look up the appropriate values.
Single Database Tables
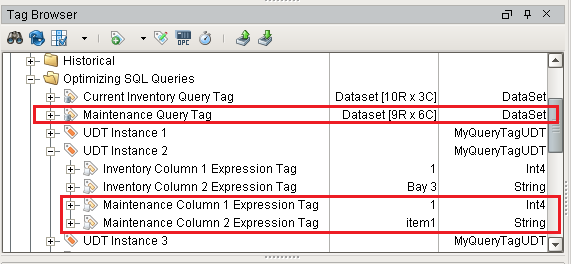
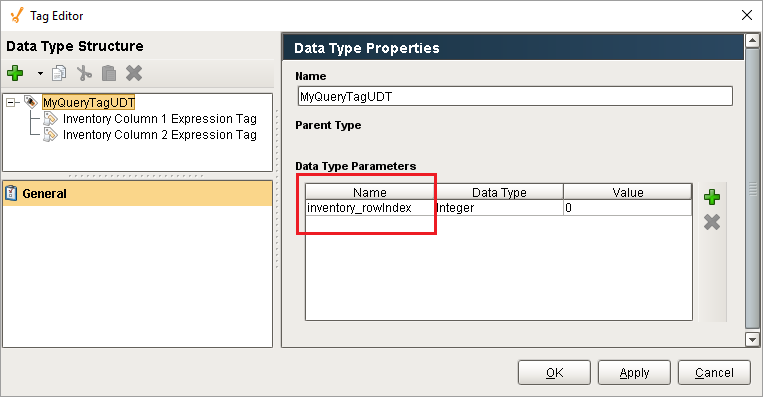
Below, the Tag named Current Inventory Query Tag, as the name implies, is a Query Tag retrieving multiple rows of data from a database table. We see that the highlighted UDT Instance 2 contains two members: Inventory Column 1 Expression Tag and Inventory Column 2 Expression Tag, which are simply Expression Tags that are referencing individual cells from the Current Inventory Query Tag.
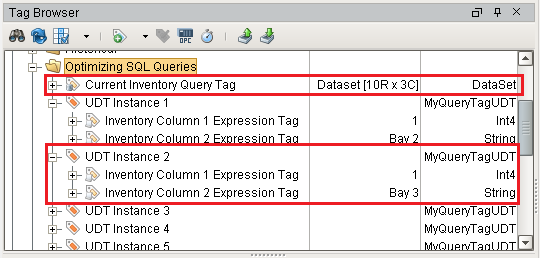
The UDT definition can use a parameter to specify an individual row in the Query Tag that each instance should focus on.
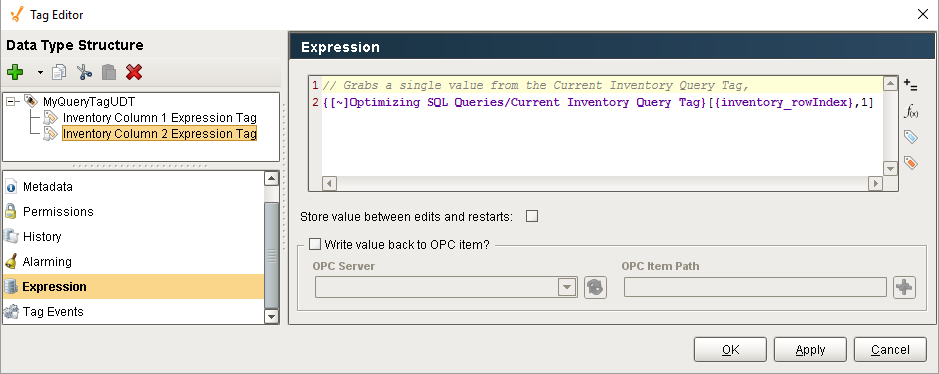
Each Expression Tag could use an expression like the following to look up individual values:
Multiple Database Tables
To add values from a separate database table, we simply need a separate Query Tag. In the image below, a new Tag named Maintenance Query Tag has been added, which is querying from a separate Database table. To incorporate this new data into our UDT instances, new Expression Tags have been added (Maintenance Column 1 Expression Tag, and Maintenance Column 2 Expression Tag) that simply reference specific values in the new Query Tag. Now, regardless of how many UDT instances exist in the Tag provider, we only have two Tags that are executing queries against the database.
For each separate table, we need to incorporate a single new Query Tag to collect all of the rows we want to show, add index parameters to the UDT definition, and add Expression Tags to our UDTs.