Custom Tag History Aggregates
Python Aggregation Functions
The Tag History system has many built-in aggregate function, such as Average, Sum, and Count. However a custom aggregate may be defined via Python scripting. These functions are used for calculations across time frames, and they process multiple values in a “window” into a single result value.
For example, if a query defines a single row result, but covers an hour of time (either by requesting a single row, or using the Tag Calculations feature), the system must decide how to combine the values. There are many built in functions, such as Average, Sum, Count, etc. Using a custom Python aggregate, however, allows you to extend these functions and perform any type of calculation.
Description
As values come in, they will be delivered to this function. The interpolator will create and deliver values. For each window (or “data block”, the terms are used synonymously), the function will get a fresh copy of blockContext. The blockContext is a dictionary that can be used to as a memory space. The function should not use global variables. If values must be persisted across blocks, they can be stored in the queryContext, which is also a dictionary.
The function can choose what data to include, such as allowing interpolation or not, and allowing bad quality or not.
The window will receive the following values, many of which are generally interpolated (unless a raw value happens to fall exactly at the time):
- The start of the window
- 1 ms before each raw value (due to the difference between discrete and analog interpolation. A value equal to the previous raw value indicates discrete interpolation)
- The raw value
- The end of the window
At the end of the window, the function will be called with “finished=true”. The function should return the calculated value(s). The resulting value will have a timestamp that corresponds to the beginning of the block time frame.
Parameters
- qval - The incoming QualifiedValue. This has:
- value : Object
- quality : Quality (which has ‘name’, ‘isGood()’)
- timestamp : Date
- interpolated - Boolean indicating if the value is interpolated (true) or raw (false)
- finished - Boolean indicating that the window is finished. If true, the return of this particular call is what will be used for the results. If false, the return will be ignored.
- blockContext - A dictionary created fresh for this particular window. The function may use this as temporary storage for calculations. This object also has:
- blockId - Integer roughly indicating the row id (doesn’t take into account aggregates that return multiple rows)
- blockStart - Long UTC time of the start of the window
- blockEnd - Long UTC time of the end of the window
- previousRawValue - QualifiedValue, the previous non-interpolated value received before this window
- previousBlockResults - QualifiedValue[], the results of the previous window.
- insideBlock(long) - Returns boolean indicating if the time is covered by this window.
- get(key, default) - A helper function that conforms to python’s dictionary “get with default return”.
- queryContext - A dictionary that is shared by all windows in a query. It also has:
- queryId - String, an id that can be used to identify this query in logging
- blockSize - Long, time in ms covered by each window
- queryStart - Long, the start time of the query
- queryEnd - Long, the end time of the query
- logTrace(), logDebug(), logInfo() - all take (formatString, Object... args).
Return Value
Your custom aggregate should return one of the following for each window:
- Object - Turned into Good Quality qualified value
- List - Used to return up to 2 values per window
- Tuple - (value, quality_int)
- List of quality tuples
Usage
Custom Python aggregates can be used in two ways:
- Defined as a Project Library script, where the full path to the function is passed to the query.
- Defined as a string, prefaced with “python:”, and passed to the query.
Currently both options are only available through the system.tag.queryTagHistory/queryTagCalculations functions.
Both of these options are used with the “aggregationMode” and “ aggregationModes” parameters to system.tag.queryTagHistory, and the “calculations” parameter of system.tag.queryTagCalculations. If the value is not an Enum value from the defined AggregationModes, it will be assumed to be a custom aggregate. The system will first see if it’s the path to a Project Library script, and if not, will then try to compile it as a full function.
For performance reasons, it is generally recommended to use the Project Library script whenever possible. For more information, see Project Library.
Conditions
There are some key factors to keep in mind when calling a custom aggregate.
Return Size
When calling a custom tag history aggregate, the returnSize argument must be set to a number greater than 0, otherwise the custom aggregate will be ignored.
Aggregate Library Project
When using a Project Library, the library must reside in the Gateway's scripting project.
Library Name
The name of the project library must start with shared, in lowercase. However there can be additional characters following the word shared. For example: shared_myLib.
Examples
Creating a Custom Function Script
-
Add a project script, by right clicking the Project Library item in the Project Browser, and choosing the New Script option.
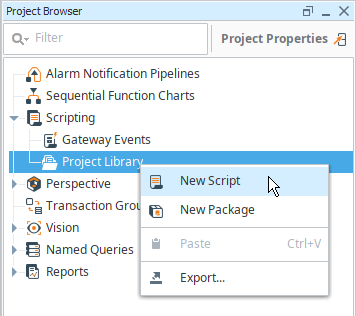
-
Enter a name for the script and click Create Script (we named ours shared in the example).
-
Enter the following code block:
Example# this is a simple count function, called for each value in a time window
def myCount(qval, interpolated, finished, blockContext, queryContext):
cnt = blockContext.getOrDefault('cnt',0)
if qval.quality.isGood():
blockContext['cnt']=int(cnt)+1
if finished:
return blockContext.getOrDefault('cnt', 0)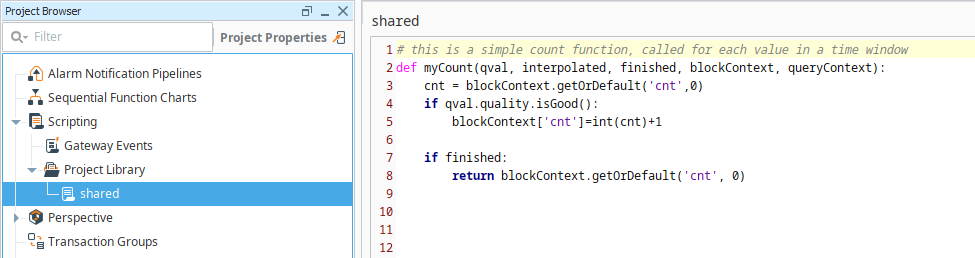
The custom function could be used by using the example below:
Example#Return tag history using a custom aggregate function you wrote.
system.tag.queryTagHistory(paths=['MyTag'], rangeHours=1, aggregationModes=['shared.myCount'], returnSize = 100)
Creating an Aggregate Function on the Fly
#Create a function on the fly to pass in as a custom aggregate.
wrapper = """\
python:def wrapper(qval, interpolated, finished, blockContext, queryContext):
return shared.aggregates.customFunction(qval, interpolated, finished, blockContext, queryContext)
"""
system.tag.queryTagHistory(paths=['MyTag'], rangeHours=1, aggregationModes=[wrapper], returnSize = 100)